Why Vector RAG Fails for AI Agent Memory
Most early attempts at AI memory (like Mem0) relied on a simple formula: take text, convert it to embeddings, and stuff it in a vector database. It works for chatting with PDFs, but for autonomous coding agents, it is a recipe for disaster. Here is why.
The RAG Illusion
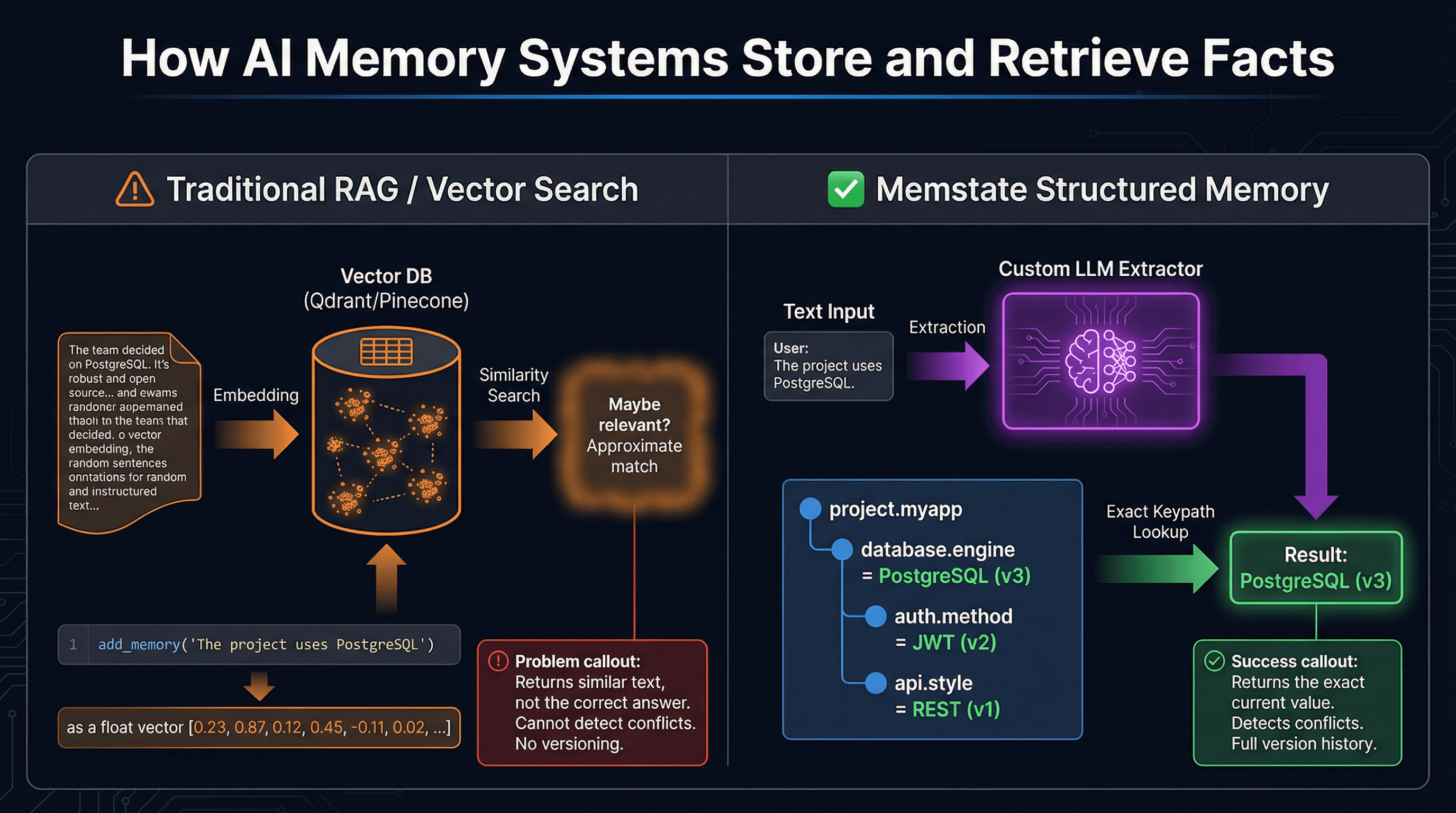
Retrieval-Augmented Generation (RAG) using vector databases (like Qdrant, Pinecone, or pgvector) is incredible at similarity search. If you want to find "articles about machine learning," a vector database will return articles with similar semantic meaning, even if they do not use those exact words.
But AI coding agents do not need similarity. They need exact facts.
When an agent asks "What database are we using?", it does not want "documents that sound similar to database choices." It wants a definitive, singular answer: PostgreSQL.
The 3 Fatal Flaws of Vector Memory
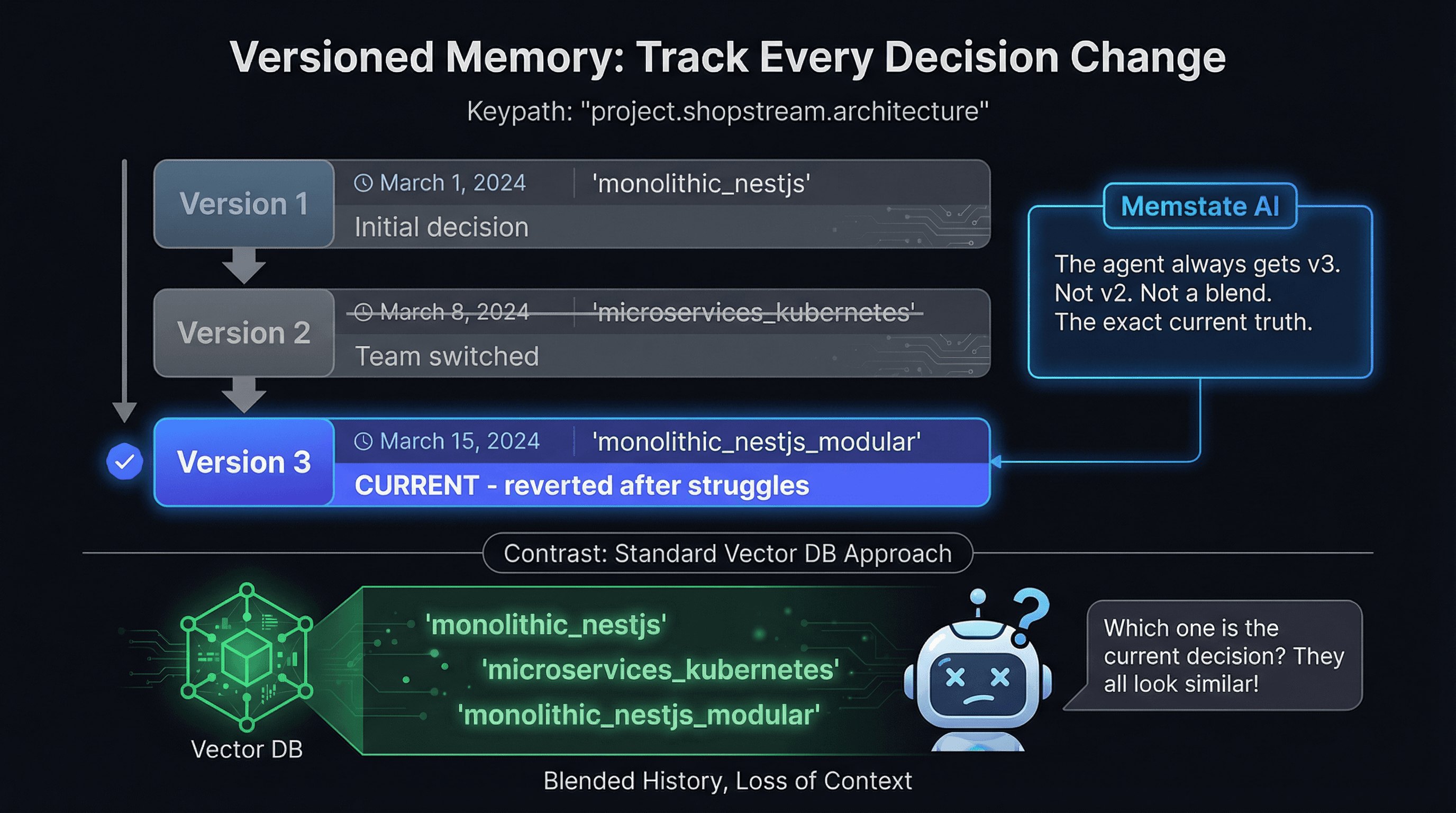
1. The Blended History Problem (No Versioning)
Imagine your project starts with MongoDB. Two weeks later, you migrate to PostgreSQL. In a vector database, both facts exist as text embeddings. When the agent queries the memory, the vector DB returns both sentences because they are both semantically relevant to "database."
The agent gets confused. Is it MongoDB or PostgreSQL? It might hallucinate a hybrid, or just guess wrong. Vector databases have no concept of time or superseded facts.
2. Inability to Detect Conflicts
If an agent tries to store "We use Tailwind CSS" when the memory already says "We use standard CSS modules," a vector DB happily stores both. It is just a bucket of text.
A proper memory system must detect that these facts are in conflict, and automatically version the data so the newer fact replaces the older one, while preserving the history.
3. Speed and Context Bloat
Vector search usually returns chunks of text (e.g., 5 paragraphs that might contain the answer). The agent then has to read all 5 paragraphs to extract the fact. This wastes tokens and slows down the agent.
The Memstate Approach: Structured Keypaths
Memstate AI is fundamentally different. It is an AI memory system layer that leverages custom-trained LLM models designed specifically for fact extraction.
Instead of storing raw text, Memstate parses the agent's input and builds a logical hierarchy of information into condensed keypaths.
- Exact Lookups:
project.myapp.database.engine = "PostgreSQL" - Automatic Versioning: When the framework changes, Memstate automatically marks the old version as superseded. No manual cleanup required.
- Zero Ambiguity: The agent always gets the current, correct answer. Not a pile of outdated context.
This architectural difference is why Memstate scores 92.2% on fact recall accuracy in independent memory benchmarks, while naive RAG systems struggle to break 40%.
Related Guides
Upgrade your agent's memory
Stop relying on vector search for exact facts. Try Memstate for free.